Accessing data
This page shows how to run your own code and access data hosted in your cloud account. It assumes that you know how to run a Spark application on Data Mechanics.
Specify data in your arguments
On Google Cloud Platform, suppose that:
- you want to run a word count Scala Application hosted at
gs://<your-bucket>/wordcount.jar - that reads input files in
gs://<your-bucket>/input/* - and writes to
gs://<your-bucket>/output - The main class is
org.<your-org>.wordcount.WordCount <input> <output>
Here is the payload you would submit:
The command above fails because the Spark pods do not have sufficient permissions to access the code and the data:
We'll now see two ways to grant access to the Spark pods.
Granting permissions to node instances
Spark pods running in Kubernetes inherit the permissions of the nodes they run on. So a solution is to simply grant access to those underlying nodes.
- AWS
- GCP
- Azure
Your data is in the same AWS account as the Data Mechanics cluster
To let your cluster nodes access your S3 buckets you need to perform the following steps:
- create a data access policy for your S3 buckets
- attach the policy to the IAM role associated to your cluster nodes
To create a policy for your cluster nodes:
- Sign in to the IAM console at https://console.aws.amazon.com/iam/ with a user that has administrator permissions.
- In the navigation pane, choose Policies.
- In the content pane, choose Create policy.
- Choose the JSON tab and define the policy. An example of policy could for cluster nodes could be:
Attach the created policy to the IAM role associated with cluster nodes:
- Sign in to the AWS Management Console and open the IAM console at https://console.aws.amazon.com/iam/.
- In the navigation pane, choose Policies.
- In the list of policies, select the check box next to the name of the policy to attach. You can use the Filter menu and the search box to filter the list of policies.
- Choose Policy actions, and then choose Attach.
- Select the IAM role associated to cluster nodes, choose Attach policy.
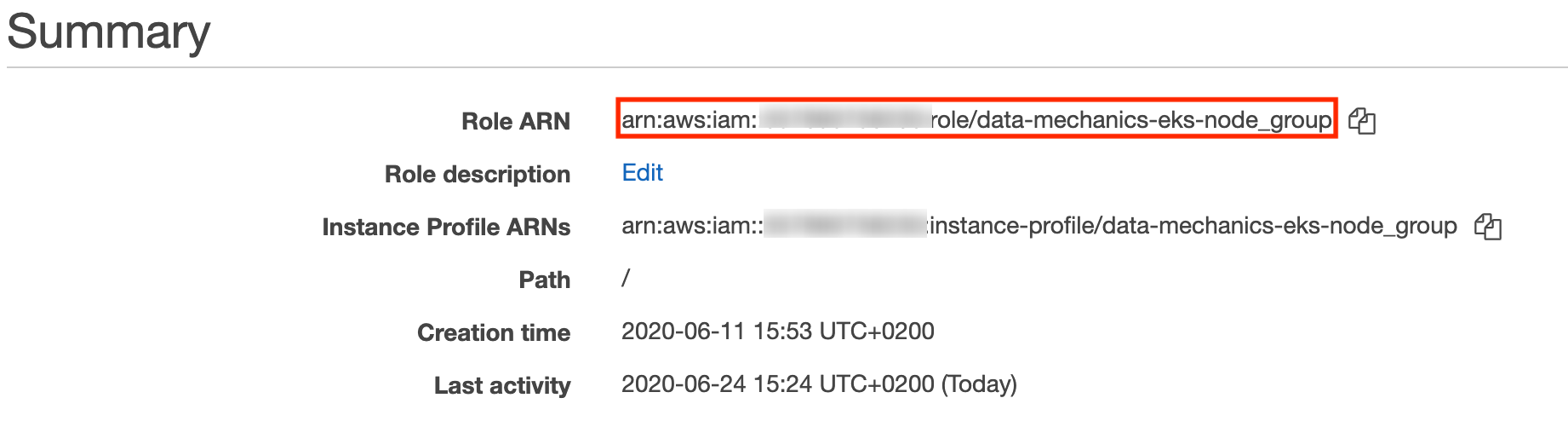
The IAM role associated to cluster nodes can be found in the Roles. tab of the navigation pane. Note down the IAM role ARN and not the instance profile ARN:
Your data is in another AWS account than the Data Mechanics cluster
To let your cluster nodes access your S3 buckets you need to perform the following steps:
- create an IAM role in the AWS account where the data lives
- add policy to grant this IAM role permissions to access the data and attach to role{"Version": "2012-10-17","Statement": [{"Effect": "Allow","Action": ["s3:*"],"Resource": ["arn:aws:s3:::<your data bucket>","arn:aws:s3:::<your data bucket>/*",]}]}
- in the IAM role's trust policy, authorize the data-mechanics-eks-node_group role associated to your cluster nodes to assume the IAM role in the data account{"Version": "2012-10-17","Statement": [{"Effect": "Allow","Principal": {"AWS": "arn:aws:iam::<data mechanics account id>:role/data-mechanics-eks-node_group"},"Action": "sts:AssumeRole"}]}
- grant the data-mechanics-eks-node_group role the ability to assume the new IAM role in the data account{"Version": "2012-10-17","Statement": [{"Sid": "Stmt1487884001000","Effect": "Allow","Action": ["sts:AssumeRole"],"Resource": ["arn:aws:iam::<data account id>:role/<IAM role in data account>"]}]}
- add the following configuration to your data mechanics submit application payload{"hadoopConf": {"fs.s3a.stsAssumeRole.arn": "arn:aws:iam::<data account id>:role/<IAM role in data account>","fs.s3a.assumed.role.arn": "arn:aws:iam::<data account id>:role/<IAM role in data account>","fs.s3a.aws.credentials.provider": "org.apache.hadoop.fs.s3a.auth.AssumedRoleCredentialProvider","fs.s3a.assumed.role.credentials.provider": "org.apache.hadoop.fs.s3a.SimpleAWSCredentialsProvider,com.amazonaws.auth.EnvironmentVariableCredentialsProvider,com.amazonaws.auth.InstanceProfileCredentialsProvider"}}
Detailed explanation can be found in the "Cross-account IAM roles" of the AWS documentation about cross-account access. For the purposes of this example, Account A referenced in the docs would be the account where data is stored, and Account B is the data mechanics account.
The IAM role associated to your cluster nodes, data-mechanics-eks-node_group, (called "the IAM role in Account B" in the AWS documentation) can be found in the Roles tab of the navigation pane of the IAM console available at https://console.aws.amazon.com/iam/ in your data mechanics AWS account. Note Use the IAM role ARN and not the instance profile ARN:
Granting permissions using Kubernetes secrets
Spark pods can impersonate a user (AWS) or a service account (GCP) by using their credentials. On Azure, a Spark pod can use a storage account access key in order to access to the storage account's containers.
To protect those credentials, we will store them in Kubernetes secrets and configure Spark to mount those secret into all the driver and executor pods as environment variables.
- GCP
- AWS
- Azure
To let your Spark pods access your S3 buckets you need to perform the following steps:
- create a data access policy for your S3 buckets
- create a user that is granted the data access policy
- create an access key for the user
- create a Kubernetes secret that contains the access key
- configure Spark to use the Kubernetes secret
Create a policy for your cluster nodes:
- Sign in to the IAM console at https://console.aws.amazon.com/iam/ with a user that has administrator permissions.
- In the navigation pane, choose Policies.
- In the content pane, choose Create policy.
- Choose the JSON tab and define the policy. An example of policy could for cluster nodes could be:
Create a user that is granted the data access policy:
- Sign in to the AWS Management Console and open the IAM console at https://console.aws.amazon.com/iam/.
- In the navigation pane, choose Users, and click on Add User.
- Give it a name and check "Programmatic access".
- Click on "Attach existing policies directly" and attach the policy you just created.
- Complete the user creation process.
A user with the correct policy is now created.
Create an access key for the user:
- Sign in to the AWS Management Console and open the IAM console at https://console.aws.amazon.com/iam/.
- In the navigation pane, choose Users, and click on the user you just created.
- Go to the "Security credentials" tab and click on "Create access key".
- Note down the access key ID and the access key secret.
Create a Kubernetes secret that contains the access key:
The command below generates a secret from the access key ID and the access key secret created in the previous steps:
Configure Spark to use the Kubernetes secret:
You can now modify the payload to launch the Spark application in order to reference the secret: