Configuration management
This page provides an overview of the different levels of configurations supported by Data Mechanics API.
Data Mechanics determines your application configurations by applying three sources of input. By order of priority:
- Config overrides. Application-specific configurations that you can specify directly in your API request. They take absolute precedence.
- Auto-tuning. Configurations which are automatically applied by Data Mechanics to improve your jobs performance and stability, based on the history of the past applications for the given job. This feature takes precedence over config templates but will be overriden by config overrides.
- Config templates. Fragments of configuration that you can define directly inside Data Mechanics and reuse across many notebooks and jobs.
This page covers all this, and gives some recommendations on how to configure your apps!
To know more about the API routes and parameters, check out the API reference.
Config overrides
Config overrides are fragments of configuration that you define when you are requesting Data Mechanics to launch a Spark application.
They are specified directly in the body of the POST /api/apps/ request:
Config overrides have higher precedence than all other sources of configuration. As a result, they are useful:
- to specify arguments that change at every execution of you Spark job. For example, if you have an ETL pipeline processing data for a specific date, you should pass this date using config overrides.
- to forcefully make sure a specific configuration is applied (so that it cannot be changed by auto-tuning or a configuration template). For example, you may have a technical reason to force Spark to use a certain codec for compression.
All other configurations are better placed in the config templates.
To know more about the configurations you can set in Data Mechanics, check out the API reference.
Config templates
Config templates are fragments of Spark application configuration stored in Data Mechanics. This can be useful when you need to share a large default configuration between applications, or when you simply don't want to store configurations on your side.
Following the example above, we'll store in a config template the stable configurations, those that don't change at every application invocation.
There are two ways you can manage the config templates in your deployment: through the Data Mechanics dashboard or through the API.
- Dashboard
- API
In the Data Mechanics dashboard accessible at https://<your-cluster-url>/dashboard/, click on the "Templates" section of the left navigation menu.
You should see the config templates already stored in your deployment:
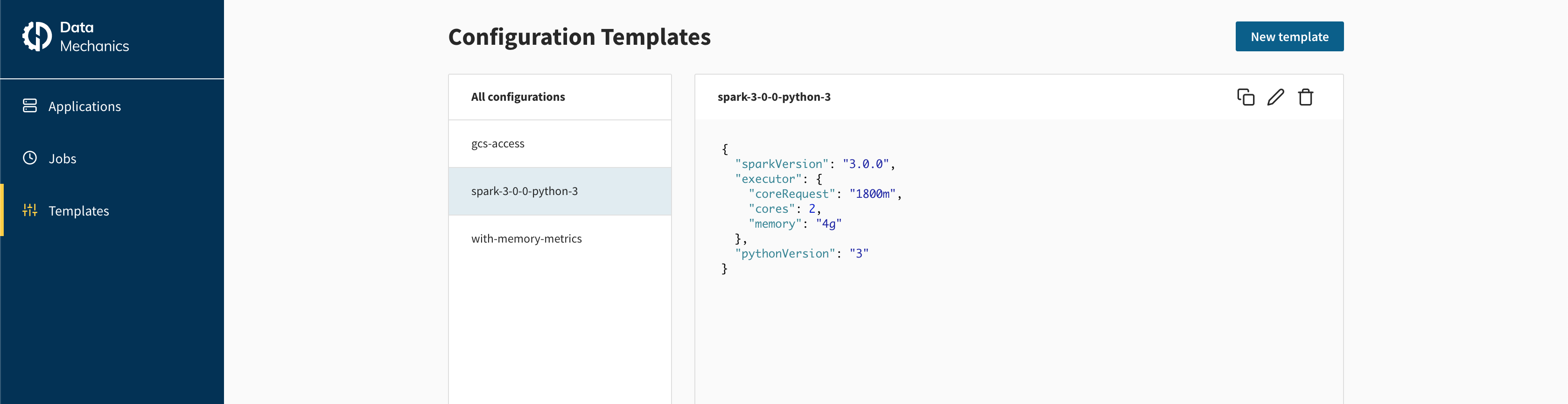
Click on "New Template" in the upper right corner and create a config template called my-template with the following content:
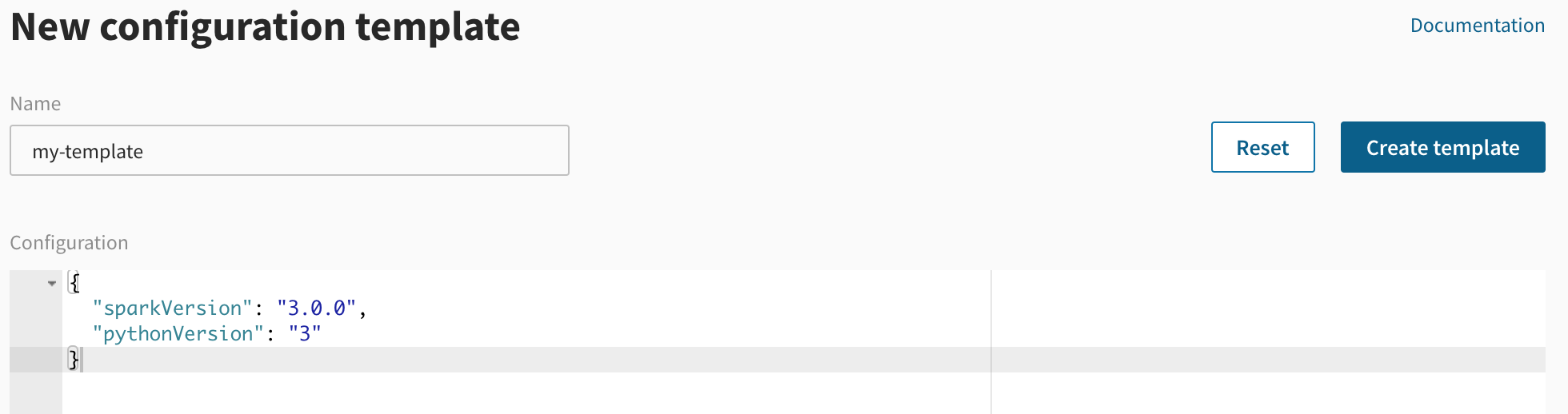
To know more about the configurations you can set in Data Mechanics, check out the API reference.
The config template can now be used as a kernel for a Jupyter notebook or referenced when submitting a Spark application using the field configTemplateName:
Data Mechanics merges the configurations in config template my-template and in the config overrides.
The configuration in configOverrides has higher precedence than the config template, since they're more dynamic.
Data Mechanics auto-tuning
Data Mechanics automatically tunes the infrastructure parameters and Spark configurations of your scheduled applications run after run, to improve their performance and stability. Under the hood, we use the information contained in the Spark History Server to tweak various performance knobs of Spark, like the pod sizes of your Spark executor or the number of partitions Spark uses by default.
This is what you see in the return payload when you launch the Spark application:
Data Mechanics has added performance configurations, so that your application smoothly runs on Kubernetes.
For the first run of your application, the platform is unaware of the specifics of your app and sets sensible default values given the different node pools attached to your Kubernetes cluster.
When you run a second application with jobName daily-upload however (say for day 2020-06-25), Data Mechanics uses the logs and metrics of the previous run 2020-06-24 to fine-tune configurations.
Day after day, this auto-tuning process continues so that performance improves without action on your part.
Controlling auto-tuning
To give you control over the tuning process, the config overrides have precedence over Data Mechanics auto-tuning, while config templates have not.
So if you want to force a parameter and not have it be auto-tuned, just put it in the config overrides. On the other hand, parameters found in config templates will be tuned by Data Mechanics when it makes sense. The values you put in the config template will serve as a starting point for the algorithm!
For example, if you set the following config fragment in the config template of your application,
Data Mechanics might change the number of executors at some point, in order to improve efficiency. If you put it in config overrides though, the number of executors will never change.
Our recommendation is to put all performance parameters in a config template, so that Data Mechanics auto-tuning can adjust them over time.