Connecting Jupyter notebooks
This page assumes that you know how to create and manage config templates on Data Mechanics.
Data Mechanics' integration with Jupyter notebooks lets you run Jupyter kernels with Spark support on your Data Mechanics cluster. You can connect your notebooks from a Jupyter or Jupyterlab server you run locally, or from a hosted JupyterHub.
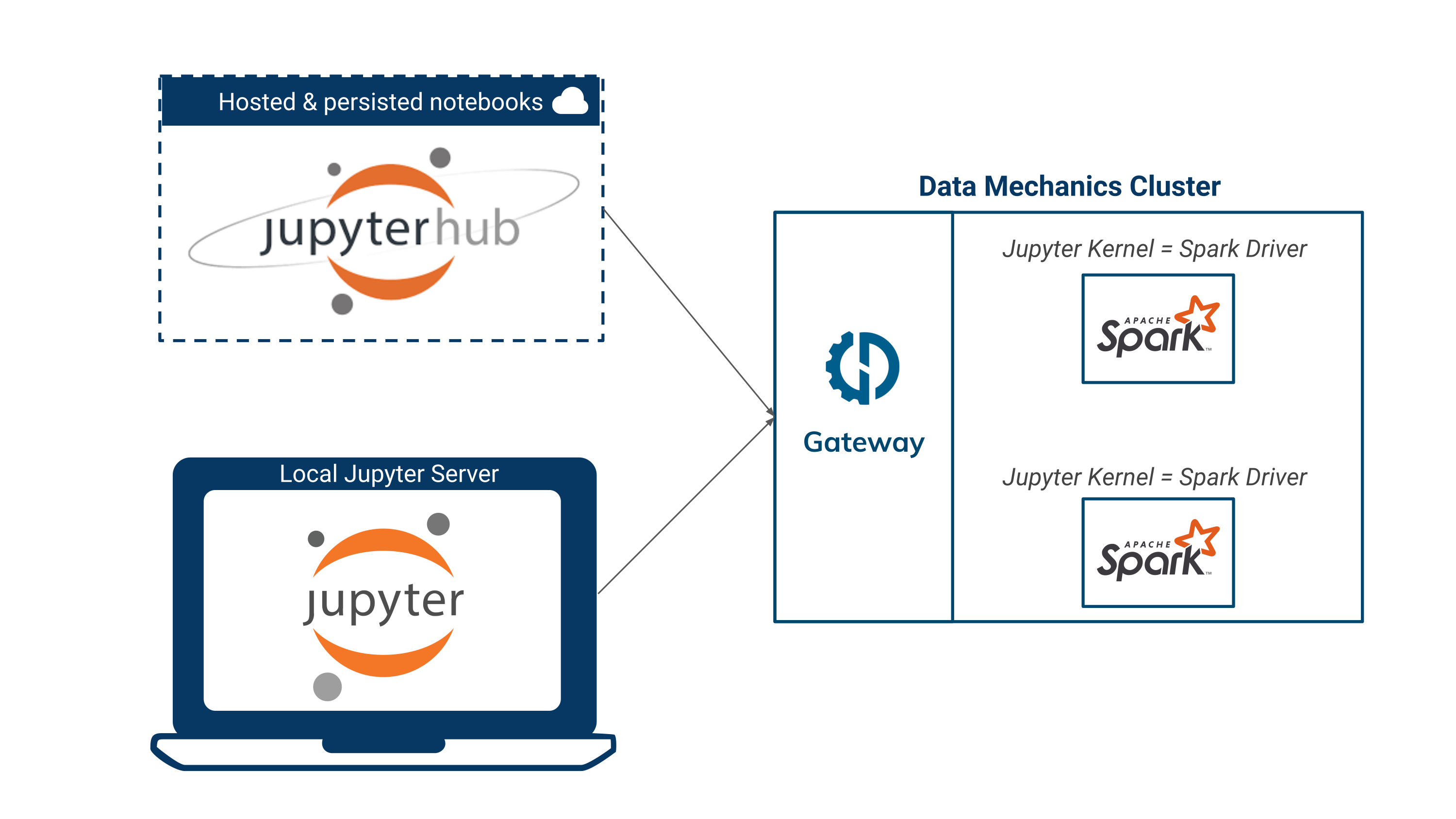
Connect a local Jupyter server
The Jupyter notebook server has an option to specify a gateway service in charge of running kernels on its behalf. The Data Mechanics gateway can fill this role and lets your run Spark kernels on the platform.
Install the Jupyter server locally. Make sure to have the latest version (≥6.0.0) with
The notebook service needs your user key to authenticate your session with the Data Mechanics API:
The request_timeout parameter specifies the maximum amount of time Jupyter will wait until the Spark driver starts.
If you have capacity available in your cluster, the wait time should be very short.
If there isn't capacity, the Kubernetes cluster will automatically get a new node from the cloud provider, which usually takes a minute or two.
We recommend setting the request_timeout to 10 minutes to give you a security margin.
Data Mechanics is also compatible with Jupyter Lab. Install with
and run with
Integrate with JupyterHub
This repository shows you how to connect a hosted JupyterHub environment to your Data Mechanics cluster. As in the local example, each user needs to provide a Data Mechanics API key before running notebooks.
Define kernels with config templates
Jupyter uses kernels to provide support for different languages and to configure of notebook behavior.
When a Jupyter server is connected to Data Mechanics, any Config template can be used as a kernel.
You can use the dashboard to create the config templates in your browser or create them programmatically:
In your Jupyter dashboard, you should now be able to create a new notebook using kernels derived from those config templates:
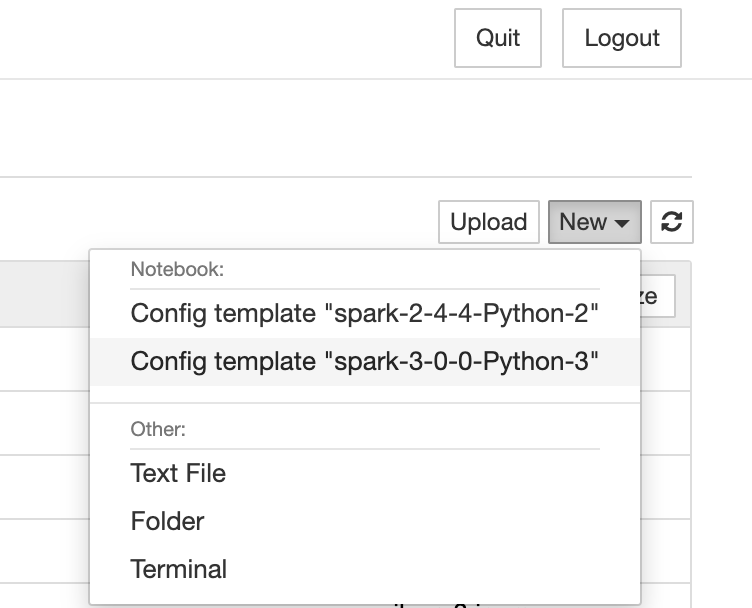
At the moment, Data Mechanics only supports Python kernels. Scala kernels are on the way.
Use a notebook
If you open a notebook, you need to wait for the kernel (ie the Spark driver) to be ready. As long as the kernel is marked as "busy", it means it has not started yet. This may take up to 2 minutes.
Here are the objects you can use to interact with Spark:
- the Spark context in variable
sc - the Spark SQL context in variable
sqlContext
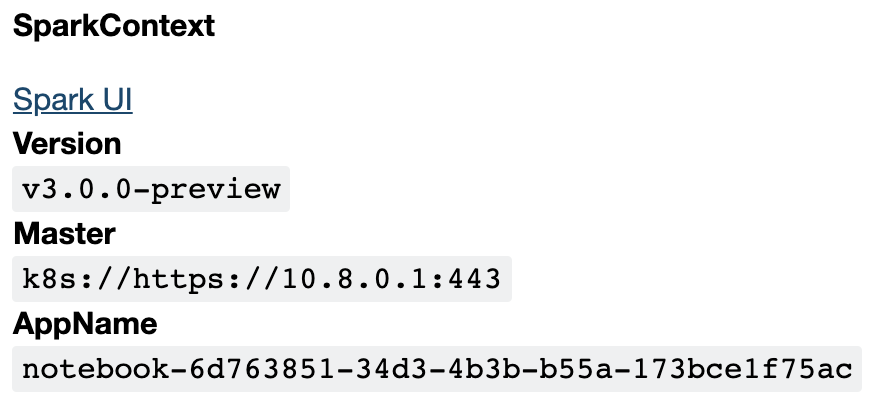
If those objects are not ready yet, you should see something like this upon invokation:
After a few seconds, they should be ready and you can use them to run Spark commands:
You can install your own libraries by running:
If you are new to Jupyter notebooks, you can use this tutorial as a starting point.
Close a notebook
To close a notebook application, you should not use the "Kill" action from the dashboard, because Jupyter interprets this as a kernel failure and will automatically restart your kernel, causing a new notebook application to appear.
You should close your notebooks from Jupyter (File > Close & Halt). This will terminate the Data Mechanics app.
Important Note
In some cases, a notebook may be "leaked", for example if the Jupyter server (running on your laptop) quits abruptly, or loses internet connection. This may leave a notebook application running on Data Mechanics without being linked to a Jupyter server. In this scenario, use the Kill action to terminate it.
Inject environment variables
If you need to pass some information from your local environment to the notebook kernel in a dynamic way, you can use environment variables.
The environment variables are only injected into the notebook kernel if they are prefixed with KERNEL_VAR_.
In the kernel, the environment variables are stripped of their prefix.
For instance, if you run the following command and open a notebook:
The env variable FOO=bar is available in the notebook:

Notebooks are normal Spark apps
Data Mechanics essentially makes no distinction between notebooks and Spark applications run by API call. All options and features of Spark applications are available to notebooks.
Notebooks appear in the Applications view, so you can see their logs and configurations, access the Spark UI, and more:
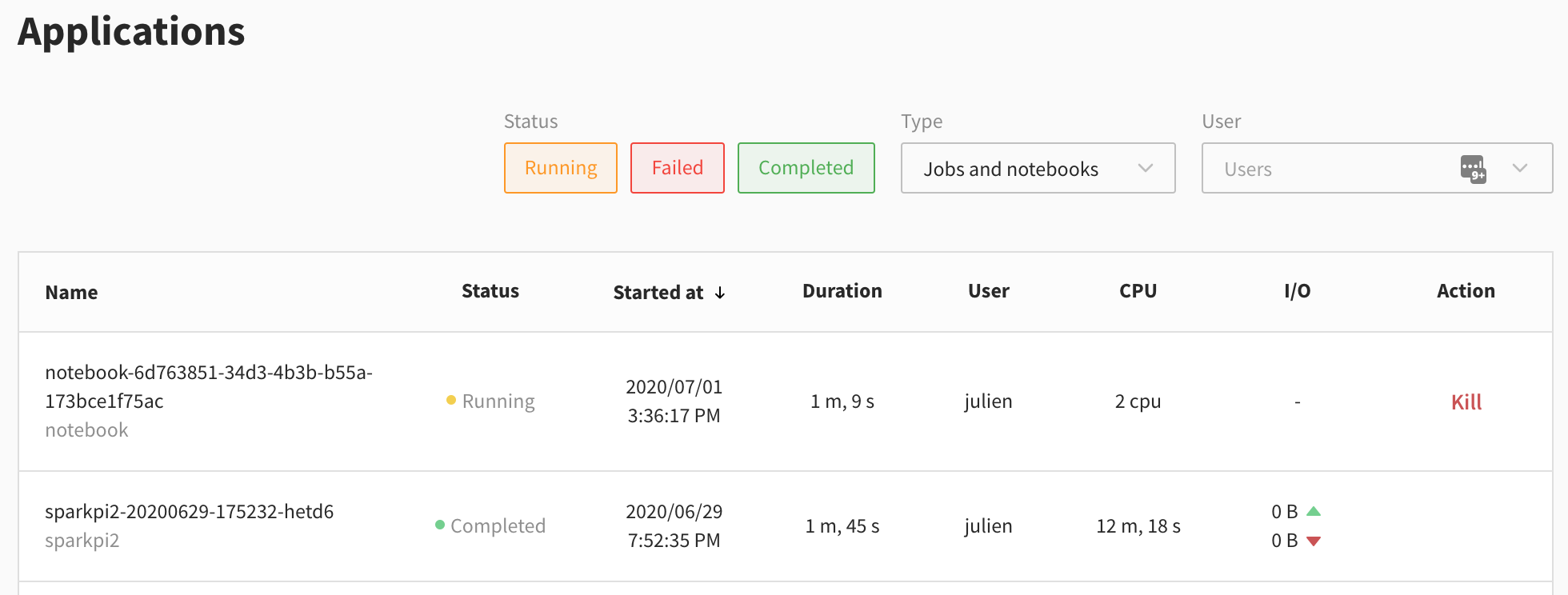
You can use the "Type" dropdown visible in the screenshot to filter on notebooks.
Additionally, any configuration option for Spark applications can be applied to notebooks via the config template mechanism.