Running apps from Airflow
This page shows how to configure Airflow to trigger Spark applications on the Data Mechanics platform.
The Data Mechanics Airflow plugin is compatible with Airflow 1 and Airflow 2.
Optional: spin up an Airflow sandbox with Docker
In the rest of this tutorial, we assume that you have access to a running Airflow environment. If this is not the case, we describe in this section how you can set up an Airflow sandbox with Docker.
If you don't need this, just skip this section!
Run a local Airflow server with:
The Airflow UI is now available at http://localhost:8080/.
Connect to the container with
When you're finished with the tutorial, kill the docker image with
Install the Data Mechanics Airflow plugin
Docker sandbox
If you use the Docker sandbox, run all the commands in this section from within the Docker container. Connect to it with:
Install the Data Mechanics Airflow plugin using pip:
Configure a connection to your Data Mechanics platform in Airflow:
- Programmatically
- In the Airflow admin console
This will create an Airflow connection Data Mechanics named datamechanics_default.
In case you don't have one already, generate an API key in your Data Mechanics dashboard at https://<your-cluster-url>/dashboard.
Create an example DAG
The example file below defines an Airflow DAG with a single task that runs the canonical Spark Pi on Data Mechanics.
- Airflow 1 (Docker sandbox)
- Airflow 2
Since, the DataMechanicsOperator is a thin wrapper around the Data Mechanics API, its arguments should feel familiar if you have already submitted an app through the API.
You can learn more about the content of the config overrides section in the API reference.
Note that if you omit the job_name argument, the Airflow argument task_id will be used as the job name.
More complex examples are available in the Data Mechanics Airflow plugin repository.
Copy the file to where your Airflow DAGs are stored, usually $AIRFLOW_HOME/dags.
Docker sandbox
If you use the Docker sandbox, copy the file into the local folder dags/.
This folder is mounted into the container's $AIRFLOW_HOME/dags/ path and the file will thus be available to Airflow.
Depending on your configuration, you may need to restart the Airflow webserver for the DAG to appear in the DAG list.
Docker sandbox
Run the DAG
Connect to your Airflow webserver (http://localhost:8080/ on the Docker sandbox).
To run the DAG, toggle the switch on the left to "On" and click on the "Play" button on the right.
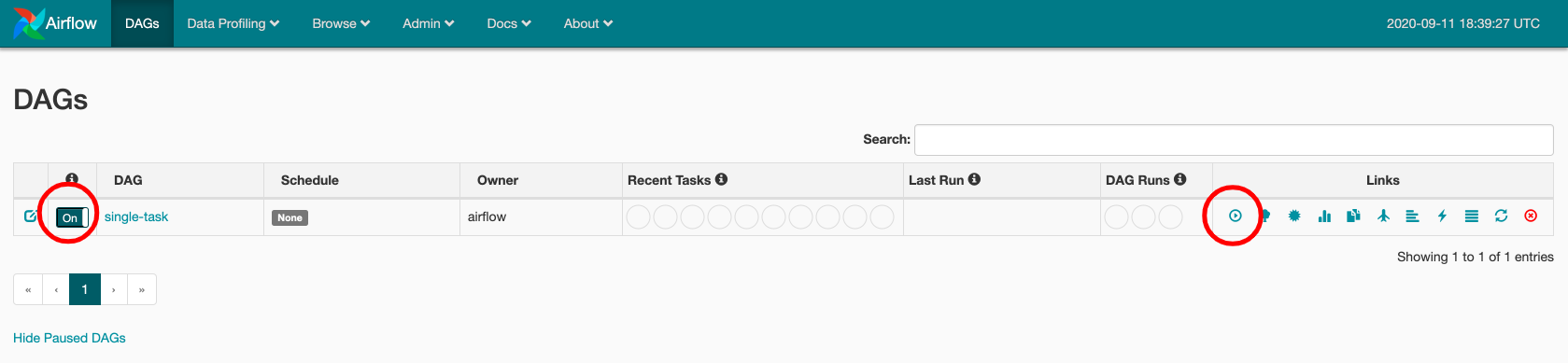
Now click on the DAG name and get to the tree view. Click on the green square to open a pop-up with more options.
If the square is not green yet, click on the "Refresh" action button.
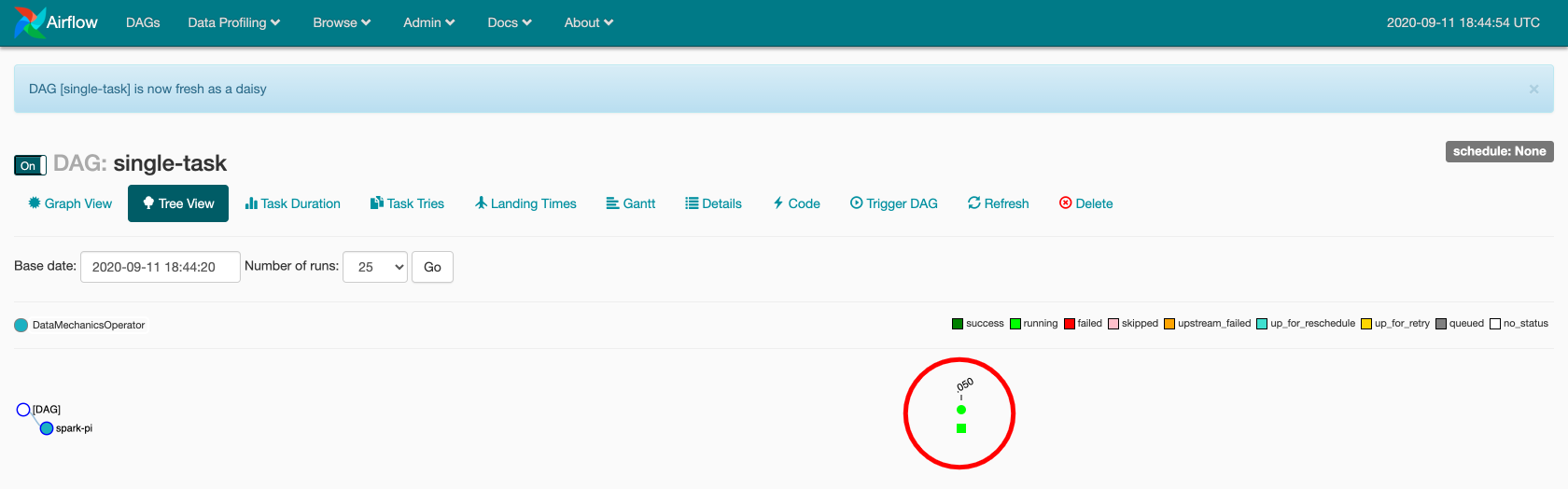
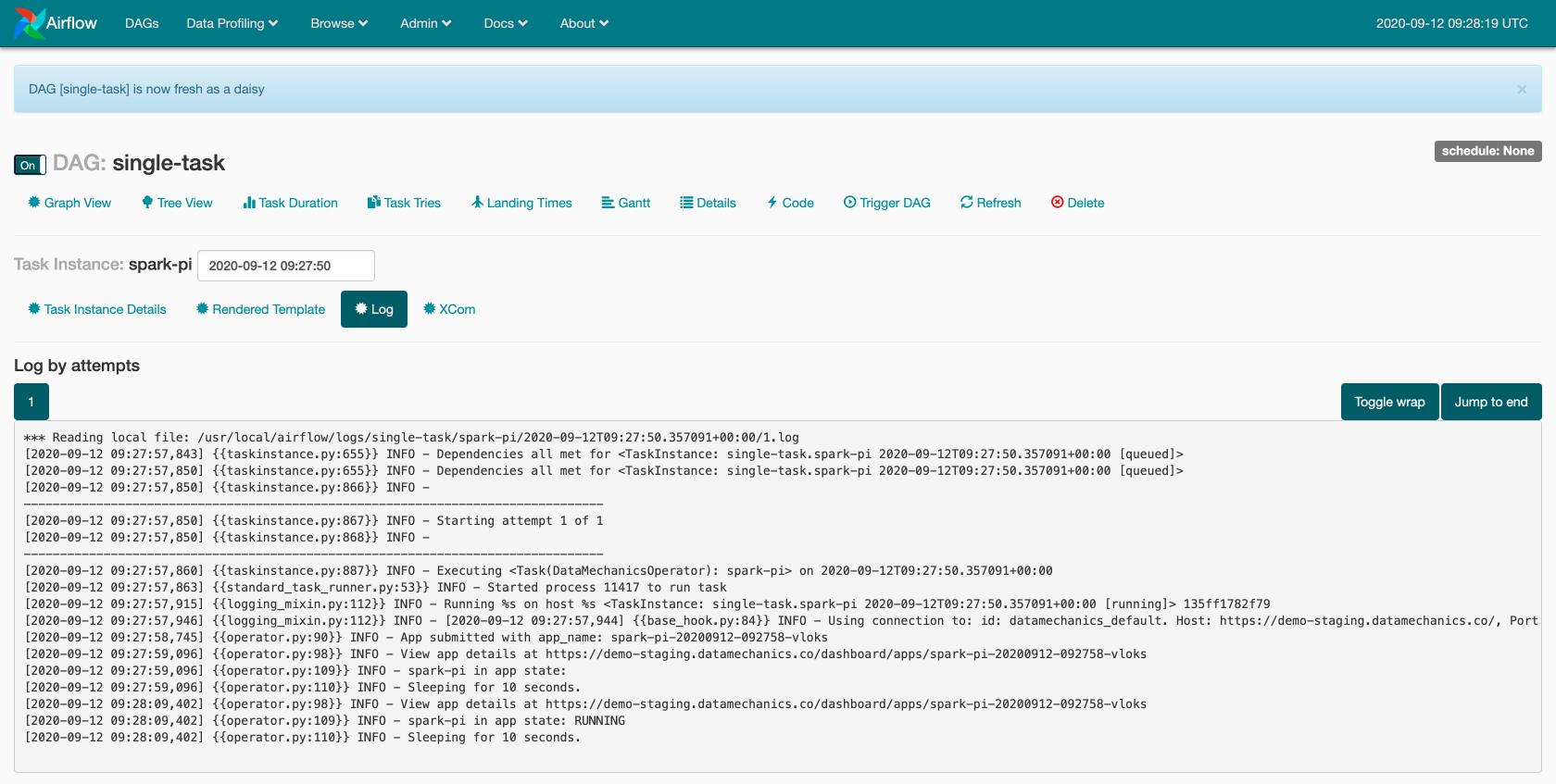
In the pop-up, click on "View log". The log shows that Airflow interacts with the Data Mechanics platform to track the status of the Spark application.
A URL to the Data Mechanics platform can also be found in the log. It brings you directly to the page of the application.
You should now be ready to schedule Spark applications on Data Mechanics using Airflow!