Memory & Cores
How to configure your Spark pods sizes and select the node pools on which they are placed.
Concepts
Your Data Mechanics deployment is made of multiple node pools. A node pool is a group of nodes that share a common instance type and other characteristics. It can scale up and down (to zero).
A node pool is defined by:
- an
instanceType(example when using AWS: m5.xlarge, r5.xlarge) - a boolean
spotindicating whether to use spot (preemptible) instances or on-demand ones
In practice, those fields are used in config templates or in config overrides like this:
Data Mechanics manages these node pools for you, from their initial definition, to their automatic scaling at runtime based on the needs of the Spark apps.
Node pools can be empty, they will automatically scale down to 0 nodes if they are unused. Therefore we can define a large number of node pools without incurring any cloud costs.
Spark applications are made of Kubernetes pods. A pod is essentially a container, placed by Kubernetes on a node pool. Each spark application is made of exactly one driver pod, and a variable number of executor pods.
In the graph below, you can see an example visualization of all the node pools and pods of a cluster:
- 5 nodes pools are defined (including an empty node pool)
- 3 Spark applications are running with various sizes of driver and executor pods (see the color coding)
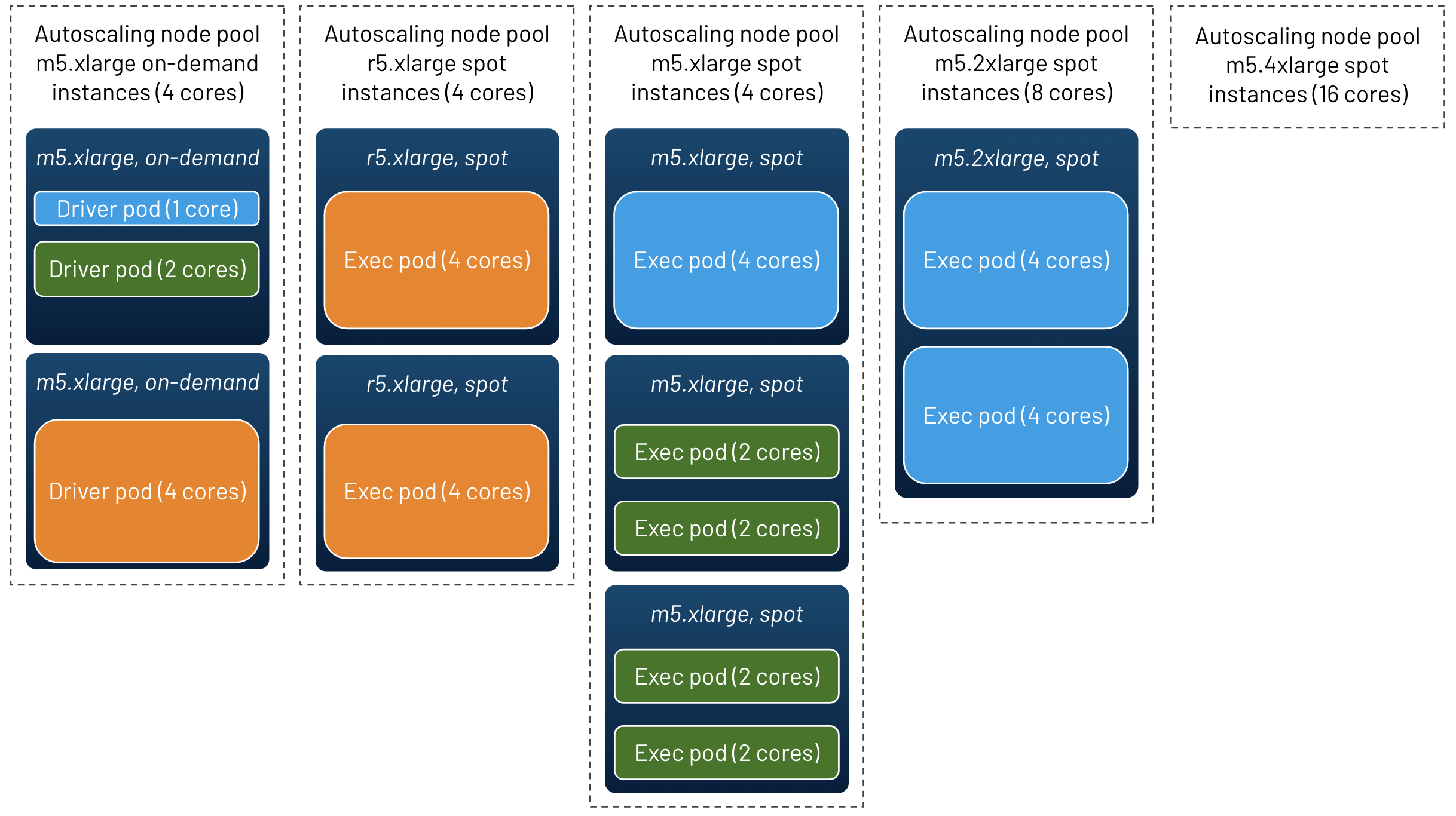
We will now see how to configure your Spark applications to control the size of the containers and the type of nodes on which they are placed.
Configuring the driver pod
Here's a fragment of a configuration which will cause the Spark driver to occupy half of an m5.xlarge instance (which has 4 cores). Put this configuration fragment in a config template or in config overrides.
There are 2 main fields to configure your driver pod:
instanceType: The type of instance to use (e.g. m5.xlarge, r5.xlarge). This field is optional, leaving it empty lets Data Mechanics pick the node pool.cores: The number of CPU cores to allocate. This field is optional and defaults to 1.
Data Mechanics will automatically pick other parameters (including memory) to optimize the bin-packing of pods onto nodes. In the example above, since you requested 2 cores of a 4-core instance, half of the node allocatable memory will be given to your driver pod.
If your application does heavy driver operations (such as running pure python/scala code on the driver, or collecting large results), it's a good idea to increase
coresto a bigger number to speed up these operations and avoid OutOfMemory errors.
Configuring the executor pods
Here's a fragment of configuration which will cause each executor pod to fully occupy an m5.xlarge instance. Put it in a config template or in config overrides.
Data Mechanics will by default size each executor pod to use all the cores of the instance it runs on, here 4 cores of an m5.xlarge instance.
There are 3 main fields to configure your executor pods:
instanceType: The type of instance to use (e.g. m5.xlarge, r5.xlarge). This field is optional, leaving it empty lets Data Mechanics pick the node pool.spot: Whether to use spot nodes or not. This field is optional and defaults to false (on-demand nodes are used by default).cores: The number of CPU cores to allocate. This field is optional, by default this will be the number of cores available in the chosen node (executor pods will fully occupy their node by default).instances: The number of executor pods to create. If dynamic allocation is activated, this is the initial number of executor pods: Spark will then adjust this number during the lifetime of the application.
Data Mechanics will automatically pick other parameters (including memory) to optimize the bin-packing of pods onto nodes. In the example above, the memory parameters will be set so that the entire node allocatable memory is given to the executor pod.
You don't need to manually reserve room for Kubernetes or for Spark on the physical nodes: Data Mechanics does it for you.
For example, if you want to run two 2-core executor pods on every m5.xlarge node, please set
instanceTypetom5.xlargeandcoresto2. Data Mechanics will automatically set aside a few milli-CPUs for the system.
Using spot nodes
Spot (also known as preemptible) instances are 70% cheaper than on-demand instances on average, but they can be reclaimed by the cloud provider at any time.
To use them on Data Mechanics, you just need to set the boolean spot field accordingly, whether you use AWS,
GCP, or Azure.
Only Spark executors can be placed on spot nodes. The driver must always be placed on an on-demand node. This is because losing a Spark driver due to a spot interruption means the application abruptly fails. On the other hand, Spark can recover from losing an executor pod and continue its work with minimal impact.
To know more about the configurations you can set in Data Mechanics, check out the API reference.
Container Memory Overhead

If your Spark executors are abruptly terminated with a Docker exit code 137, it means that the total amount of memory used by the processes running
your containers have exceeded the memory limit. This is known as an OOM-Kill (OutOfMemory-kill).
A common situation when this can occur is when you're using PySpark - because some of your code will be executed by Python processes (1 per core) running inside your container (alongside the main Spark executor JVM process).
This can also occur when using Scala or Java, simply because in certain situations the Java Virtual Machine can use more memory than what is configured as the maximul heap size.
To remediate this issue, you should increase the memoryOverheadFactor configuration, for example by setting
Advanced configurations (memory, coreRequest)
The (instanceType, cores, and spot) fields should give you sufficient control over your Spark configurations to serve most of your use cases.
For example, if you want to allocate a lot of memory to your Spark driver, you could set the following configuration (put it in a config template or in config overrides):
In this example, Data Mechanics will automatically adjust the memory configuration so that the driver container fits tightly on a r5.xlarge instance.
If you'd like to control the amount of memory allocated to the Spark driver or the Spark executors precisely yourself, you can directly set the
memory field, for example "memory": "8.5g".
Note that each instance type has a maximum amount of allocatable memory, which is smaller than the memory advertised by the cloud provider. This is due to the overhead of memory used by Kubernetes and the system.
Another advanced configuration available to you is the coreRequest field, which controls the number of CPU cores requested by Spark from Kubernetes, while
the cores field controls the number of tasks to run in parallel on each Spark executor.
By default, coreRequest matches the cores field (with only minor adjustments made by Data Mechanics to optimize bin-packing), but you can decide otherwise,
for example by setting (put it in a config template or in config overrides):
This will cause Spark to schedule 4 tasks in parallel on each Spark executor, even though only 2 CPUs are allocated to them.
Note that 2000m means 2000 milli-CPUs in Kubernetes lingo.
If you'd like to investigate some of these configurations further, the official documentation page on Running Spark on Kubernetes contains some useful information.