What is Data Mechanics
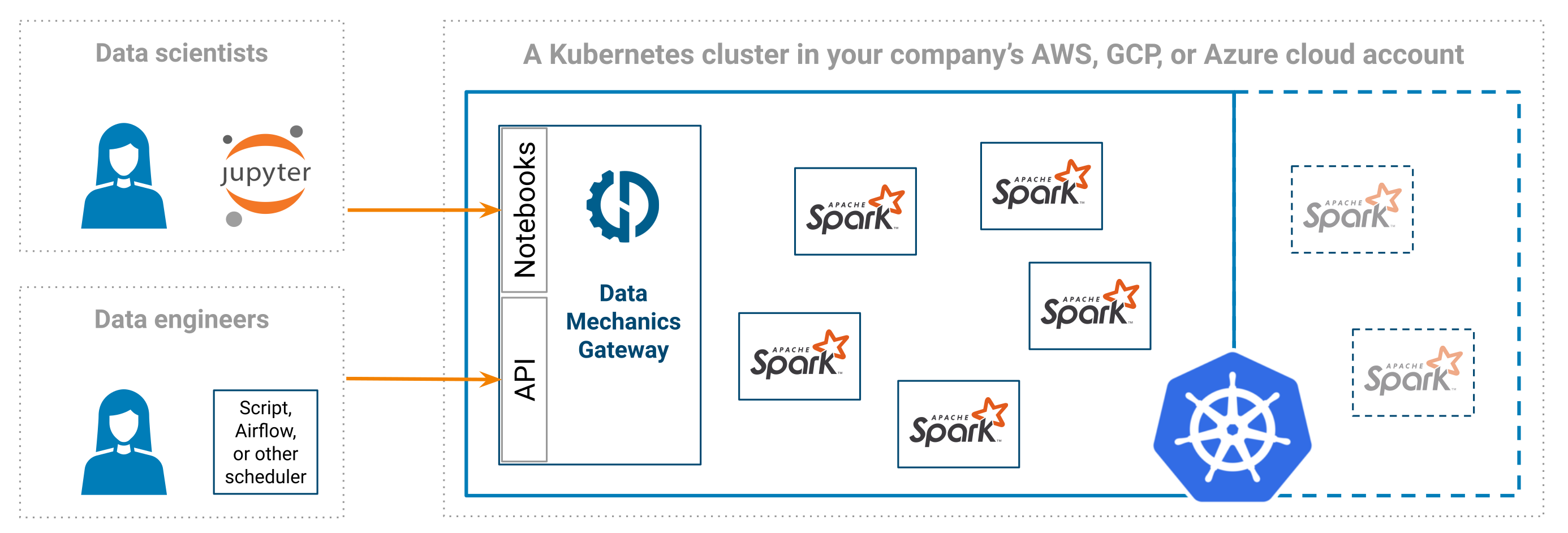
Data Mechanics is a managed Spark platform - a more developer-friendly and cost-effective alternative to services like Databricks, EMR, Dataproc, Azure HDInsight, etc. It is deployed on a Kubernetes cluster inside your cloud account (AWS, GCP, or Azure).
This means your sensitive data does not leave your cloud account. In fact, the cluster can be made private such that you can only access it through your company's private network.
We handle the creation and management of the Kubernetes cluster (using EKS on AWS, GKE on GCP, and AKS on Azure), and automatically scale its node pools up and down according to the load.
When signing up, we require a set of permissions from you. We use these permissions for the initial deployment, for updating the platform with new releases and security fixes, as well as for providing support upon your request.
One small node holding the Data Mechanics Gateway stays up all the time. The Gateway is the entrypoint for launching Spark applications:
- You can connect a Jupyter notebook and play with Spark interactively.
- Or submit apps programmatically through our API or our Airflow connector.
The gateway also serves a web dashboard where you can:
- Monitor apps: you can view the Spark driver logs, the Spark UI, and more metrics.
- Monitor jobs (an application that you run repetitively): you can track the history of your performance, cost, and stability metrics over time, and see the impact of our auto-tuning feature.
If there's any question you can't find the answer for, ask us directly through the live chat!