Creating an External Hive Metastore
This page shows how to create an external Hive metastore database. It assumes that you are familiar with creating a database service in your cloud provider.
Having an external detastore Database is necessary to make your Hive metadata persistent accross Data Mechanics applications and jobs. It is also a way to share Spark tables between Spark platforms.
Data Mechnanics supports the Hive local mode in which the persistent database is accessed by the local Hive service that is automatically spawned on the Spark driver of Data Mechanics Spark applications and jobs.
Creating the Hive metastore external database involves the following steps:
- Creating a database service in your cloud provider
- Configuring the database connectivity to ensure the Database is accessible from Data Mechanics
- Creating the Hive metastore database
- Creating the Hive schema
Creating a Database Service
On AWS you have many choices among which RDS. RDS allows you to create managed services for Aurora, MySQL, MariaDB, PostgreSQL, Oracle, Microsoft SQL Server.
AWS instructions to create RDS and PostgreSQL can be found here.
You should consider carefully availability, backups, security and maintenance. Refer to the AWS documentation.
This page gives an example for RDS and PostgreSQL.
Configuring Connectivity
One way to insure connectivity is to create an inbound rule for TCP on port 5432 and to ensure the database is publicly accessible.
Inbound rule
Go to the VPC security group of the Database service and create an inbound rule similar to the following:

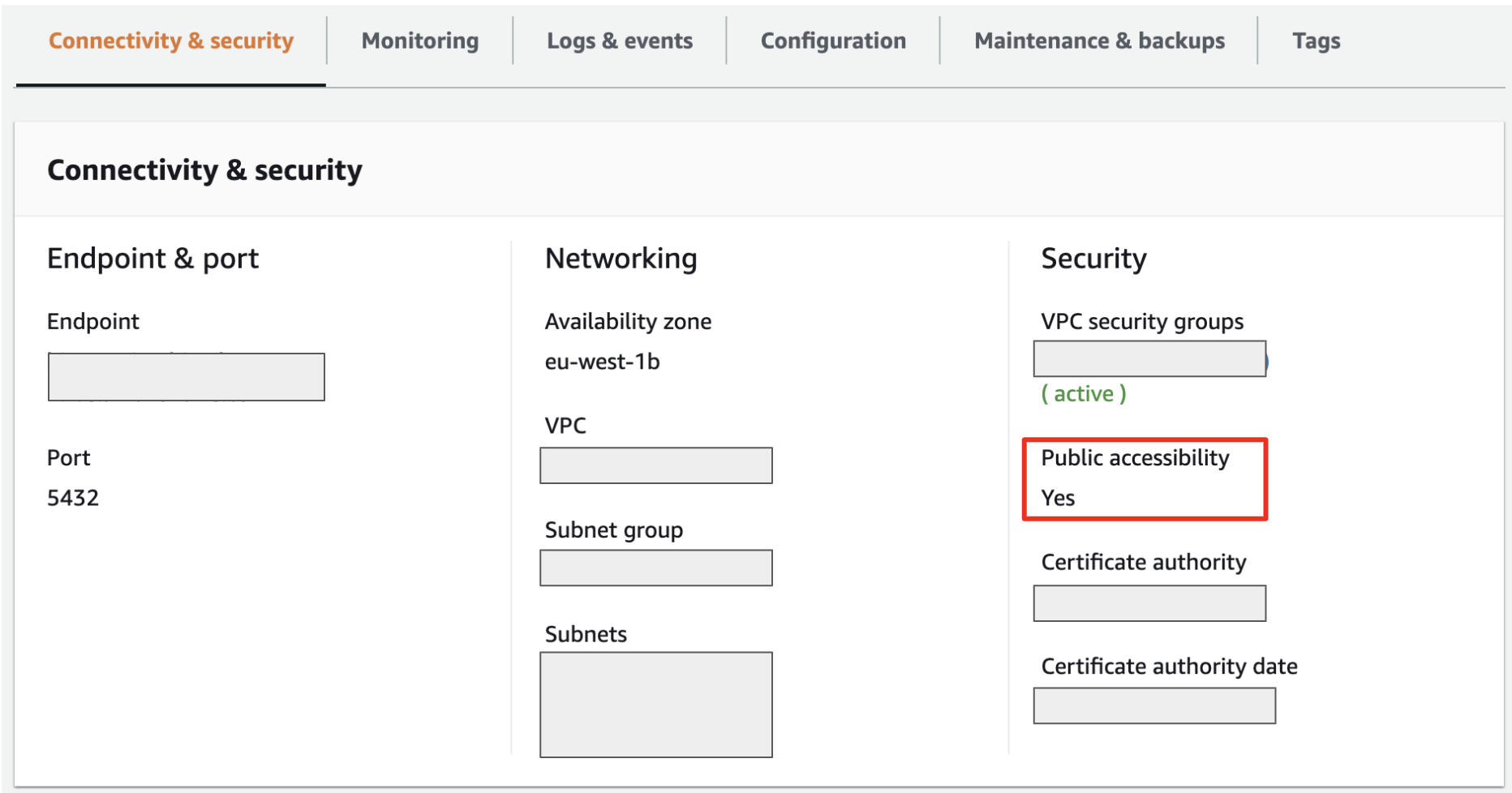
Public Access
You can follow the instructions here. The connectivity of your RDS service should be like this:
Creating the Hive metastore database
One way to do it is through a database client tools like pgAdmin or Postico. From one of those tools create a connection to your database service and create a database that will store all the Hive metadata.
Creating the Hive schema
The last step to prepare the Hive metastore is to create the Hive schema. You need to retrieve the following two sql scripts:
Look for \i hive-txn-schema-2.3.0.postgres.sql; in the first script and replace it with the content of the second script.
Then run the whole in your database client tool.
The above scripts are for Hive 2.3 and PostgreSQL. You will find scripts for other Hive versions and databases here
Regarding the Hive version, 2.3 is the Spark default and unless you have specific constraints you should choose this version.